机器之心发布
机器之心编辑部
自然语言处理(Natural Language Processing)是人工智能的核心问题之一,旨在让计算机理解语言,实现人与计算机之间用自然语言进行通信。阿尔伯塔大学(Universityof Alberta)刘邦博士在他的毕业论文《Natural Language Processing and Text Mining with Graph-Structured Representations》中,对基于图结构(graph-structured representations)的自然语言处理和文本挖掘进行了深入研究。
这篇博士论文将自然语言处理和文本挖掘的多个核心任务与图结构的强大表示能力结合起来,从而充分的利用深度学习的表示能力和文本中的结构信息来解决诸多问题:(1)组织信息(Information Organization):提出了基于树/图结构的短文本/长文本对的分解算法以提高语意匹配任务(semantic matching)。基于文本匹配,进一步提出事件粒度的新闻聚类和组织系统 Story Forest;(2)推荐信息(Information Recommendation):提出了 ConcepT 概念挖掘系统以及 GIANT 系统,用于构建建模用户兴趣点以及长短文本主题的图谱(Ontology)。构建的兴趣图谱 Attention ontology 有助于对用户与文本的理解,并显著提高推荐系统的效果;(3)理解信息(Information Comprehension):提出了 ACS-Aware Question Generation 系统,用于从无标注的文本中生成高质量的问答对,大幅度的降低问答系统的数据集构建成本,并有助于提高阅读理解系统的效果。
论文链接:https://sites.ualberta.ca/~bang3/files/PhD-Thesis.pdf
引言
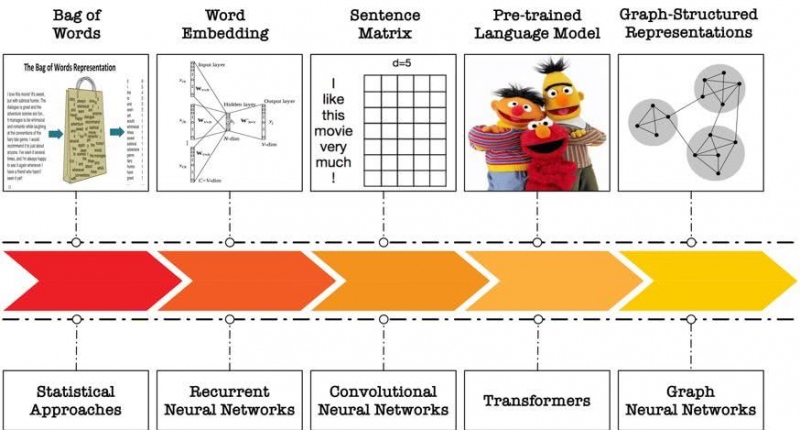
自然语言处理(NLP)旨在读取和理解未结构化的自然语言文本来完成不同的任务。「如何表示文本」以及「怎么样做计算」是其中的两个核心问题。早期的 NLP 研究中,利用 bag-of-words 模型表示文本,通过统计不同单词的频次来形成文本的向量表示,同时结合统计办法来进行文本处理,这丢失了文本的词序信息以及单词之间的联系,本质上是用 one hot encoding 来表示每个单词;在深度学习中,研究者根据单词的共现来学习词向量,每个单词由一个 dense vector 表示,语意相似或联系紧密的词在向量空间中距离更小,再结合 RNN 模型(LSTM,GRU 等)进行文本编码完成各种任务;其后又有研究工作将文本类比图像,编码形成矩阵表示,结合 CNN 类模型进行计算;近年来,预训练语言模型,利用自监督学习训练各类大型语言模型,从而给单词或文本赋予上下文敏感的(context-sensitive),多层的语义向量表示,其采用的模型是多层的 Transformer。
自然语言的形式及其语意具有层次性(hierarchical),组合性(compositional)和灵活性(flexible)。已有的研究并未充分的利用各类文本中存在的语义结构。图(graph)是一种通用且强大的表示形式,可以表达各种不同对象以及它们之间的联系,无论是在自然语言处理,还是在社交网络,现实世界等各种场景都无处不在。本论文在深度学习强大的表示学习能力的基础上,设计并结合了不同的文本的图结构化表示,并利用图结构计算模型,例如图神经网络(Graph Neural Networks), 去解决不同的自然语言处理和文本挖掘问题。论文包含三大部分:第一部分介绍了文本的聚类和匹配,提出各类匹配问题的结构化算法,并进一步提出 Story Forest 系统用于新闻事件的聚类组织和结构化表示。该系统落地到腾讯 QQ 浏览器热点事件挖掘。第二部分关注文本挖掘,提出了 Attention ontology 兴趣图谱,挖掘和描述用户不同粒度的兴趣点,建立不同兴趣点之间的联系,并可用于刻画文章主题。这部分工作显著提高了 QQ 浏览器,手机 QQ,微信等应用中的信息流推荐系统的效果。第三部分关注文本生成,提出了 ACS-QG 系统,自动从无标注文本中生成高质量的问答对,可用于问答系统的训练,有助于大幅度减少数据集创建成本,以及提高机器阅读理解的能力。
图 1. 文本表示形式以及计算模型的演化
图 2. 论文的组成框架
第一部分:文本的匹配与聚类
第三章 Story Forest 事件聚类组织系统
在信息爆炸的年代,查询并找到有价值的信息,对用户而言并不是格外的简单的任务。目前的搜索引擎或者信息流服务,会给用户更好的提供一个文章列表。这些新闻文章会包含大量冗余信息,缺乏结构化的组织。本文提出 Story Forest 系统,对新闻文章做事件(event)粒度的聚类,使得报道同一个现实中的事件的不同文章聚类成一个节点,相关联的事件形成结构化的故事树(story tree), 来表征关联事件之间的时间顺序和发展关系。
图 3.「2016 年美国总统大选」的故事树,树中的每一个节点代表一个事件
已有的文本聚类方法不能很好地对文章进行事件粒度的聚类效果。本文提出 EventX 聚类算法,它是一种双层聚类算法:在第一层聚类中,利用所有文章中的关键词,形成关键词网络(Keyword Graph)并对其进行图分割,分割后的每一个关键词子图,代表一个大的话题,再利用相似度将每篇文章分配到一个最相似的关键词子图之下;在第二层聚类中,每一个关键词子图下的文章形成一个文章图(doc graph), 相连的边代表两篇文章讲述同一个事件,再对文章图进行社区检测(community detection),从而做了第二次聚类。每一个文章子图里的文章代表一个事件。通过双层聚类,即可以对文章对之间做细粒度的语义比较,又可以控制时间复杂度。在得到事件聚类之后,不同的事件节点通过故事结构组织算法,在线插入到已有的故事树中形成故事结构。如果一个事件不属于任何已有的故事树,则形成一个新的故事。
图 4. Story Forest 系统以及 EventX 聚类算法
第四章 基于图分解和图卷积的长文本匹配
文本匹配是判断两个文本之间的关系或者相关度,是 NLP 中的核心问题,有很多的任务其核心都可视为一个文本匹配任务。根据匹配的源文本和目标文本的长短,我们大家可以将文本匹配任务分成四大类:长文本匹配任务,例如 Story Forest 系统中,一个核心的任务是判断两个文章是否在讲同一个事件;短-长文本匹配,例如输入 query 搜索匹配的文章;短文本匹配,例如问答对匹配,句子对相似度衡量等;长-短文本匹配,例如文本主题分类等等。
图 5. 根据源文本和目标文本的长短,将不同文本匹配任务分成四类
本章专注于长文本匹配任务,这是很重要的研究问题,然而在此之前,很少的研究工作专注于此。已有的算法基于 Siamese Neural Network 或者 CNN 来编码句子对或者句子之间的交互,无法很好的处理长文本匹配的任务。因为长文本的长度,导致计算复杂度较高;语言的灵活性,导致文本对之间对应的内容难以对齐;同时编码器也难以准确地编码长文本的语义。
本文提出 Concept Interaction Graph 用于分解一篇或者一对文章。其主要思想是「化整为零,分而治之」。CIG 中的每个节点包含几个高度关联的关键字,以及和这些关键字高度相关的句子集。当进行文本对匹配时,每个节点包含来自两篇文章的两个句子集。这样,多个节点代表了两篇文章中的不同的子话题,并囊括了文章中的一部分句子并进行了对齐。节点之间的边代表不同子话题之间的联系紧密度。
图 6. 根据文章构建 Concept Interaction Graph 的 toy example
基于 Concept Interaction Graph,论文进一步提出通过图神经网络(Graph Neural Networks)对文本对进行局部和全局匹配。具体而言,对每个节点上的文本对,利用编码器进行局部匹配,从而将长文本匹配转化为节点上的短文本匹配;再通过图神经网络来将文章结构信息嵌入到匹配结果中,综合所有的局部匹配结果,来得到全局匹配的结果。
图 7. 基于 Concept Interaction Graph 和图卷积神经网络的长文本匹配
第五章 基于层次化分解和对齐的短文本匹配
对于短文本匹配,论文提出了层次化句子分解(Hierarchical Sentence Factorization)来将句子分解为多层的表达,每一层都包含完整的所有单词,并且语句重排列为「predicate-argument」的顺序。随着层数的增加,一个句子逐渐被分解为更加细粒度的语义单元。因此,利用这种多层次,重排序的句子表示,我们大家可以对齐两个句子,并结合不同的语义粒度去比较他们的语义距离。
图 8.基于层次化句子分解(Hierarchical Sentence Factorization)的句子匹配
这种句子分解技术利用了 Abstract Meaning Representation 来对句子做 semantic parsing。然后,它通过一系列的操作,使得每一层都包含句子中的所有单词。对于每一个语义单元,都是谓词(predicate)在前,参数(argument)在后。这种表示充分展现了自然语言的层次性,组合性,并利用归一化的词序来克服自然语言表达的灵活顺序。
基于句子的层次分解,论文进一步提出无监督的 Ordered Word Mover's Distance, 结合了最优传输理论的思想去建模句子之间的语义距离。其效果经试验验证显著优于 Word Mover's Distance。同时,论文也提出了将句子的多语义粒度表达,应用于不同的文本匹配模型中,例如 Siamese Neural Networks 中。实验证明,多粒度的匹配效果,显著优于只利用原句进行匹配的效果。
第二部分:文本挖掘
第六章 ConcepT 概念挖掘系统
概念蕴涵了世界的知识,促进了人类的认知过程。从文档中提取概念并构建它们之间的联系对于文本理解以及下游任务有着重要的作用。认识「概念」(concept)是人类认识世界的重要基石。例如,当看到本田思域(Honda Civic)或者现代伊兰特(Hyundai Elantra)时,人们可以联想到「油耗低的车」或者「经济型车」这类的概念,并且能进而联想到福特福克斯(Ford Focus)或者尼桑 Versa(Nissan Versa)等车型。
图 9. 人类能对事物进行概念化并产生联想
过去的研究工作,包括 DBPedia, YAGO, Probase 等等知识图谱或者概念库,从维基百科或者网页文章中提取各种不同的概念。但是这样提取的概念和用户的认知视角并不一致。例如,与其认识到丰田 4Runner 是一款丰田 SUV 或者说是一种汽车,我们更感兴趣是否能把它概念化为「底盘高的汽车」或者「越野型汽车」。类似地,如果一篇文章在讨论《简爱》,《呼啸山庄》,《了不起的盖斯比》等电影,如果我们能认识到它在讨论「小说改编的电影」这个概念,那么会帮助极大。然而,目前的知识图谱等工作目的是建立一个关于这样一个世界的结构化知识表示,概念提取自语法严谨的文章。因此,它们不能从用户的视角去对文本(例如 query 和 document)进行概念化,从而理解用户的意图。另一方面,目前的工作也主要在于提取长期稳定的概念,难以提取短时间出现的热门概念以(例如「贺岁大片」,「2019 七月新番」)及它们之间的联系。
我们提出了 ConcepT 概念挖掘系统,用以提取符合用户兴趣和认知粒度的概念。与以往工作不同的是,ConcepT 系统从大量的用户 query 搜索点击日志中提取概念,并进一步将主题,概念,和实体联系在一起,构成一个分层级的认知系统。目前,ConcepT 被部署在腾讯 QQ 浏览器中,用以挖掘不同的概念,增强对用户 query 意图的理解和对长文章的主题刻画,并支持搜索推荐等业务。目前它已经提取了超过 20 万高质量的基于用户视角的概念,并以每天挖掘超过 11000 个新概念的速度在不断成长。ConcepT 系统的核心算法架构同样适用于英语等其他语言。
图 10. ConceptT 概念挖掘流程:从用户搜索点击日志中挖掘概念
ConcepT 系统还可以用于给文章打上概念标签。主要包含两种策略:基于匹配的标记算法和基于概率推断的标记算法。
图 11. ConcepT 文章标记流程:将文章打上关联的概念标签
图 12. ConcepT 系统从用户搜索 query 中提取的概念展示
图 13. 在线 A/B test 结果。ConcepT 系统对 QQ 浏览器信息流业务各项指标有明显提升。其中最重要的指标曝光效率(IE)相对提升了 6.01%。
图 14. ConcepT 系统对文章打上概念标签。目前每天可处理 96700 篇文章,其中约 35% 可以打上概念标签。我们创建了一个包含 11547 篇文章的概念标记数据用以评测标记的准确率。人工评测发现,目前系统的标记准确度达 96%。
第七章 用户兴趣点建模 Attention Ontology
上一章中,我们介绍了概念挖掘系统。为了更加全面的刻画用户兴趣点,我们进一步挖掘包括概念(concept)和事件(event),话题(topic)等等在内的多种短语,并和预定义的主题(category)以及实体库中的实体(entity)等形成上下位等关系。我们将这个包含多种节点,多种边关系,用于用户兴趣点或关注点建模的图谱命名为 Attention Ontology。
图 15. Attention Ontology,包含五种节点,代表不同语义粒度的用户兴趣点;三种关系,代表节点之间的上下位,包含,以及关联。
Attention ontology 能解决「推荐不准」和「推荐单调」的问题。例如:当一个用户看了关于「英国首相特蕾莎梅辞职讲话」的文章后,目前基于关键词的推荐系统可能会识别关键词「特蕾莎梅」,从而推荐给用户很多关于特蕾莎梅的文章。然而这大概率并不是用户的兴趣点。这是「推荐不准」的问题,原因主要在于系统中缺乏或无法识别合适粒度的兴趣点。另一方面,系统也可能继续推荐更多关于「英国首相特蕾莎梅发表演讲」的文章,这些文章与用户已经浏览过的文章产生了冗余,无法带给用户更多有价值的信息,因此用户也不感兴趣。这是「推荐单调」的问题,而这样的一个问题的本质在于缺乏不同兴趣点之间的联系。
Attention ontology 中包含不同粒度的用户兴趣点,并且不同的节点之间有边来表示它们之间的联系。例如根据 Attention Ontology,我们大家可以认识到「特蕾莎梅辞职讲话」是和「英国脱欧」这一中等粒度的兴趣点相关的。如果用户浏览了「英国脱欧」这一兴趣点下的不同事件的文章,我们便可以识别出用户不是关注「特蕾莎梅」这个人或者「特蕾莎梅辞职演讲」这一个特定事件,而是关心「英国脱欧」这一话题。而另一方面,知道了用户关注这一话题之后,利用不同兴趣点之间的联系,我们大家可以给用户推荐相关的文章,从而解决推荐不准和推荐单调的问题。
为了挖掘不同性质的短语,如概念和事件短语,论文提出了 Query-Title Interaction Graph(QTIG)用于建模 query 文章 title 之间的联系。这种表示结构将不同 query 和 title 之间的对齐信息,词的 tag,词之间的距离,语法依赖等等信息嵌入在节点特征和边的特征中。利用这种表示,论文进一步提出 GCTSP-Net 模型,将短语挖掘问题建模为「节点分类+节点排序」的问题。该模型对 QTIG 进行节点二分类,抽取出属于目标短语的词;再将节点排序建模为一个旅行商问题,寻找一个最优路径将所有的分类为正的节点进行排序。按照得到的路径,将分类为正的节点串联起来,便得到了输出短语。
图 16. Query-Title Interaction Graph. 图中绿色节点为属于输出短语的词。每一个节点代表 query 或 title 中的一个独特的词,边代表两个词相邻或者存在语法依赖。
论文设计并实现了构建 Attention ontology 并将其应用在不同应用中的 GIANT 系统。GIANT 系统包含几大模块:首先,按照每个用户的搜索 query 和点击日志形成的二分图,来进行聚类得到不同的 query-doc clusters。每个 query-doc cluster 包含一个或多个相似的 query,以及他们的 top 点击的文章。对每一个 query-doc cluster, 我们将其转化为 Query-Title Interaction Graph 表示,并利用 GCTSP-Net 抽取潜在的短语。接下来,我们再利用不同的算法去抽取不同短语之间的关系,形成 Attention Ontology。最后,利用 Attention ontology 去实现多种应用,包括文章的 tagging,query 的概念化,文本的聚类组织等。同时,Attention ontology 中的节点可用于在用户画像中描述用户的兴趣点。这样做才能够提高用户和其感兴趣的文章之间的匹配,从而提高推荐系统的效果。
图 17. GIANT 系统架构
第三部分:文本生成
第八-九章 问答对自动生成
问题生成是一种很重要的文本生成问题,它可以应用在问答系统的训练数据生成,对话系统,教育等等应用中。
图 18. 问题生成的不同应用及重要性
已有的问题生成系统一般给定一句话和一个答案,要求系统生成某个特定的问题。这种系统属于 answer-aware question generation 系统。然而,它们生成的问题质量并不够好。一个核心问题在于,给定输入的句子和一个答案,我们能问出多个不同的并且合理的问题,是「一对多匹配(one-to-many mapping)」,而训练集中每个输入只有一个标准答案,是「一对一匹配(one-to-one mapping)」。
图 19. 根据同样的输入可以问不同的问题
本文提出 answer-clue-style aware question generation(ACS-QG)任务,将人提问的过程建模成四步:第一,根据输入选择一部分作为答案(answer);第二,选择一部分和答案相关的信息作为线索(clue)在问题中复述或转述;第三,根据答案选择问题的种类(style),例如 who, where, why 等等,共 9 种;第四,根据输入的句子和以上三种信息(答案 answer,线索 clue, 问题种类 style),生成问题。
图 20. 根据输入生成问题的过程
问题生成的过程可以从语法树的角度去观察:选择答案片段就像是从语法树中覆盖了一部分信息,而选择线索片段(clue)的过程就是在覆盖的信息附近,选择一部分节点作为提示输出到问题中。
图 21. 利用语法树建模问题生成过程
本文提出的 ACS-QG 系统,可以从无标注的句子中,生成高质量的问答对数据。它由以下模块组成:数据集创建模块,可以从目前已有的问答数据集(例如 SQuAD)中,创建 ACS-QG 任务的训练数据集;输入选择模块,可以从无标注的句子中,合理的选择和创建(answer, clue, style)三元组作为问题生成的输入;问题生成模块,可通过输入三元组生成问题,这个模块的训练数据来自于第一个数据集创建模块;质量控制模块,用于过滤低质量的问答对。
图 22. ACS-QG 问题生成系统
实验证明,ACS-QG 系统能生成大量高质量的问答对,并且效果显著优于一系列已有的问题生成算法。
第十章 结论和未来工作
本论文利用图结构建模了一系列 NLP 问题中的文本数据,并结合深度学习模型,提高了多种任务的效果。论文中的各种研究,对信息的聚类组织,推荐,以及理解有着重要的意义。
未来的研究方向包括:长文本理解,多任务协同学习,以及通用的基于图结构的表示,学习与推理。
本论文中的研究已经发表在 SIGMOD,KDD,ACL,WWW,TKDD,CIKM 等各类 top conference 中,论文列表可在作者本人主页找到:https://sites.ualberta.ca/~bang3/publication.html
本文为机器之心发布,转载请联系本公众号获得授权。
------------------------------------------------

